Same Questions. New Models. Mixed Results.

Large language models are often judged on complex benchmarks, but some of their most interesting failures show up on questions that seem trivial at first glance. In this article, we test a range of OpenAI models using a small set of deliberately easy questions, the kind that have a track record of catching LLMs out. We aren't looking to build a ranking, but to build intuition about how their behaviour changes over time. Overall, performance has improved, but not always in the ways you might expect, with a few results that challenge the idea that newer models are automatically better at the basics.
Run it yourself
All of our data, code and results are available in GitHub: https://github.com/MachinesDoItBetter-ai/llm-easy-questions
An OpenAI API Key is required, so there is some cost to run.
The Experiment
Approach
We started by defining a small set of questions based on examples that large language models have historically struggled with, despite appearing straightforward. These were intentionally easy questions, chosen to expose behaviours rather than to act as a formal benchmark.
Using a simple Python script, we queried a range of OpenAI models and asked each model to answer every question under the same conditions. The models tested were:
gpt-3.5-turbo
o3-mini
gpt-4.1-nano
gpt-4
gpt-4o
gpt-4o-mini
gpt-5
gpt-5.2
For each question, the script evaluated responses using a predefined list of acceptable answers to determine whether the output was correct or incorrect. To reduce the risk of false positives or negatives, we also performed a manual review pass over the results to confirm accuracy.
To make the outcomes easier to interpret, each question was assigned to a broad category, such as Letter Counting or Mathematics, allowing us to look at patterns rather than just individual answers.
All tests were executed five times using the OpenAI API with a single (paid) API key. All runs were executed on January 2, 2026.
The Questions
The following table shows the questions used in this experiment, along with their categories and canonical answers.
| Category | Question | Canonical Answer |
|---|---|---|
| CALCULATION | What is 2345 + 9987 + 12003 + 4567? | 28902 |
| CALCULATION | What is the remainder when 123456 is divided by 7? | 4 |
| LETTER_COUNTING | How many times does the letter r appear in the word strawberries? | 3 |
| LETTER_COUNTING | Is the word "blue" longer than the word "red"? | Yes |
| LETTER_COUNTING | Does the word "bookkeeper" contain two consecutive pairs of double letters? | Yes |
| LOGIC | If every employee is a person does that mean every person is an employee? | No |
| LOGIC | Bob always rides his bike to work. Yesterday Bob did not ride his bike to work. Does Bob always ride his bike? | No |
| LOGIC | If you have three apples and I take away two oranges how many apples do you have? | 3 |
| LOGIC | A farmer has 10 sheep and all but 7 run away. How many are left? | 7 |
| MATHEMATICS | Is a circle a polygon? | No |
| MATHEMATICS | Is one a prime number? | No |
| RIDDLE | If John's father has five sons: North, South, East, and West, what is the fifth son's name? | John |
| RIDDLE | How many months have at least 28 days? | 12 |
| RIDDLE | Albert's father has a brother called Donald. Donald has three nephews: Huey, Dewey, and whom? | Albert |
Results
Overall Performance by Model
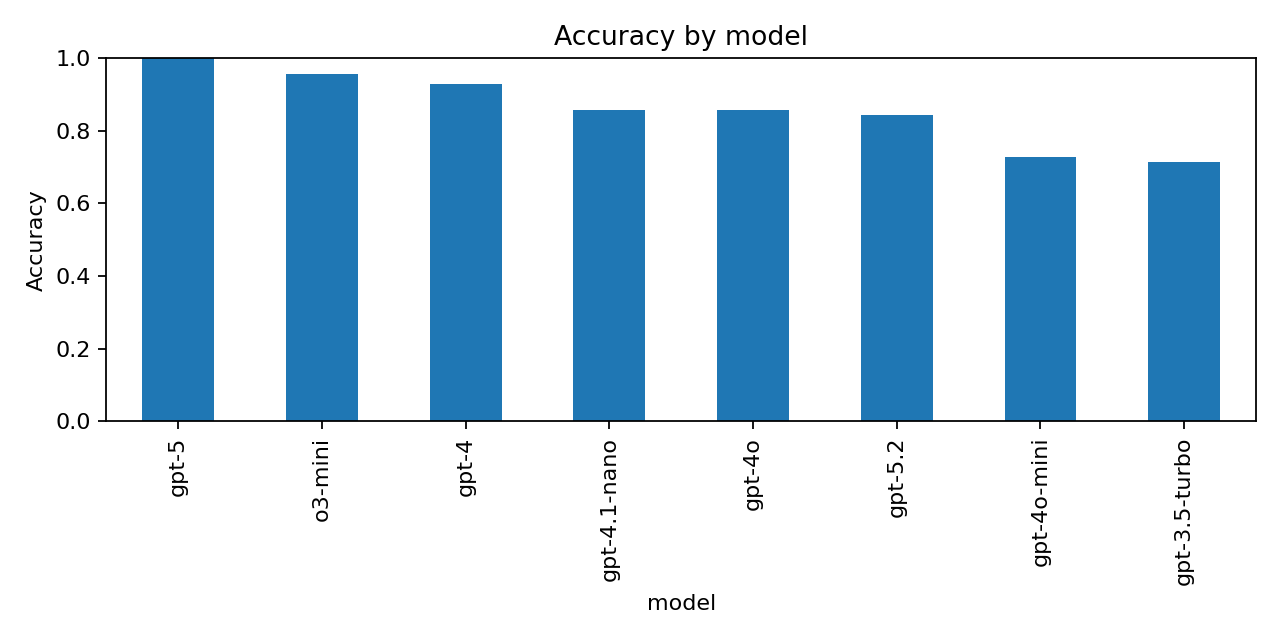
GPT-5 was the strongest performer in this set, achieving perfect accuracy across all questions. More interestingly, GPT-5.2 performed noticeably worse, consistently miscounting letters in strawberries and failing the Huey–Dewey riddle. This suggests that improvements in newer releases are not always uniform across all types of reasoning, particularly on simple but brittle tasks.
An additional surprise was that GPT-4 outperformed GPT-4o, despite the latter being a more recent and more general-purpose model. Similarly, o3-mini ranked second overall and performed better than GPT-4o, which may reflect differences in optimisation priorities rather than raw capability.
Taken together, these results reinforce the idea that model progress is not strictly linear: newer models tend to improve overall, but can regress on specific classes of “easy” questions, particularly those that rely on precise symbolic or lexical reasoning.
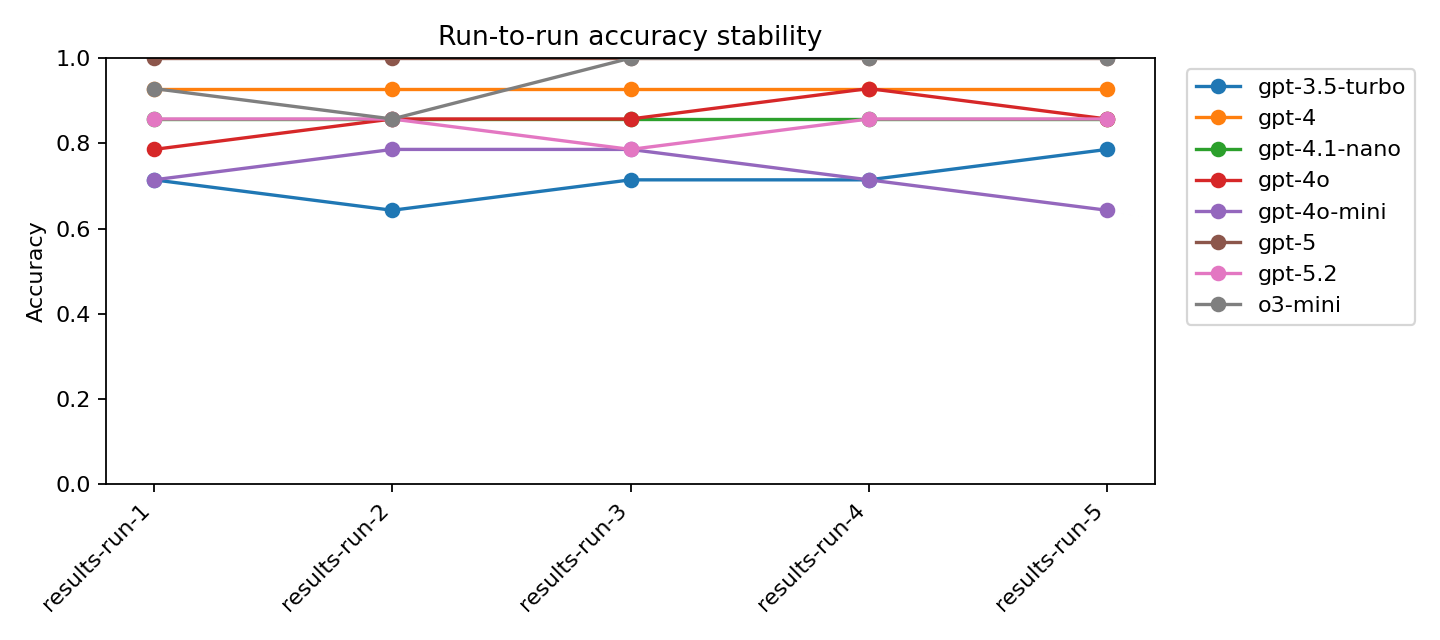
The following tables show overall accuracy by model, sorted from best to worst performer, along with consistency across runs for each model.
Performance by Category
The following table shows performance by category across all models:
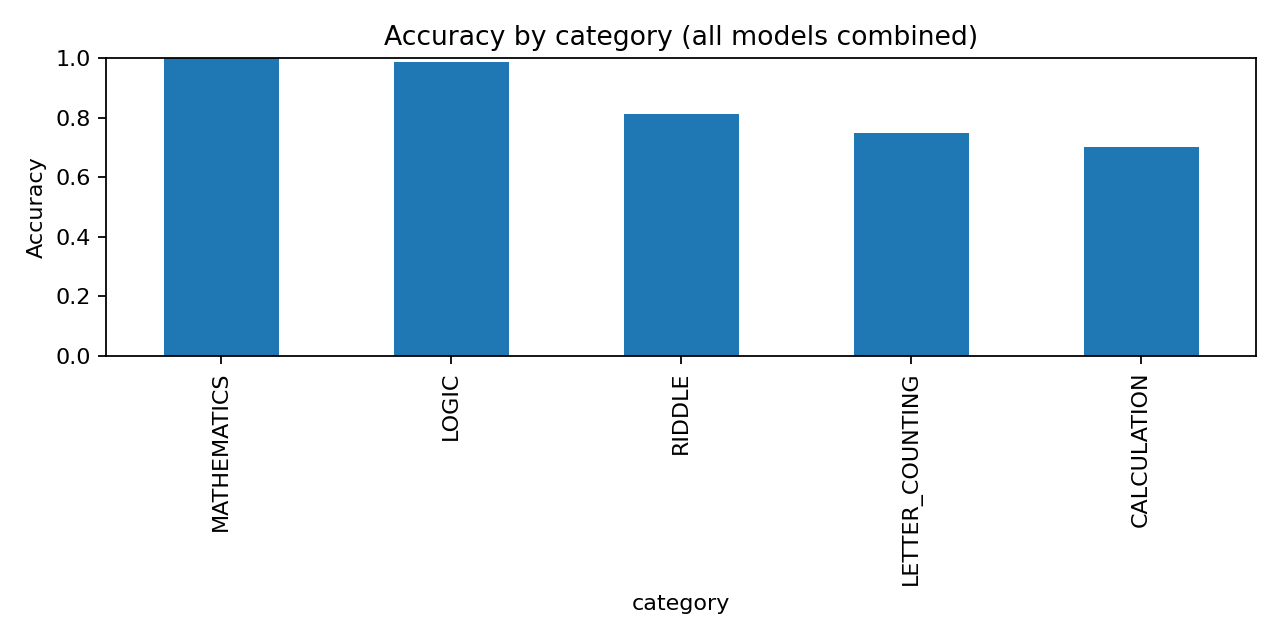
Letter counting, riddles, and mathematical questions proved to be the most challenging categories overall, particularly for older models.
Letter Counting Deep Dive
One of the most unexpected results in this experiment came from letter counting. These questions are a classic weak spot for language models, largely because they’re built around tokens and patterns rather than individual characters. That said, newer models have been steadily improving here, which makes the results from GPT-5.2 particularly surprising.
To dig in, we ran a small set of straightforward letter-counting questions across all models:
| Question | Answer |
|---|---|
| How many times does the letter i appear in the word times? | 1 |
| How many times does the letter o appear in the word countout? | 2 |
| How many times does the letter m appear in the word mammal? | 3 |
| How many times does the letter r appear in the word strawberries? | 3 |
| How many times does the letter s appear in the string drwasjaldhssiness? | 5 |
And the results were surprising:
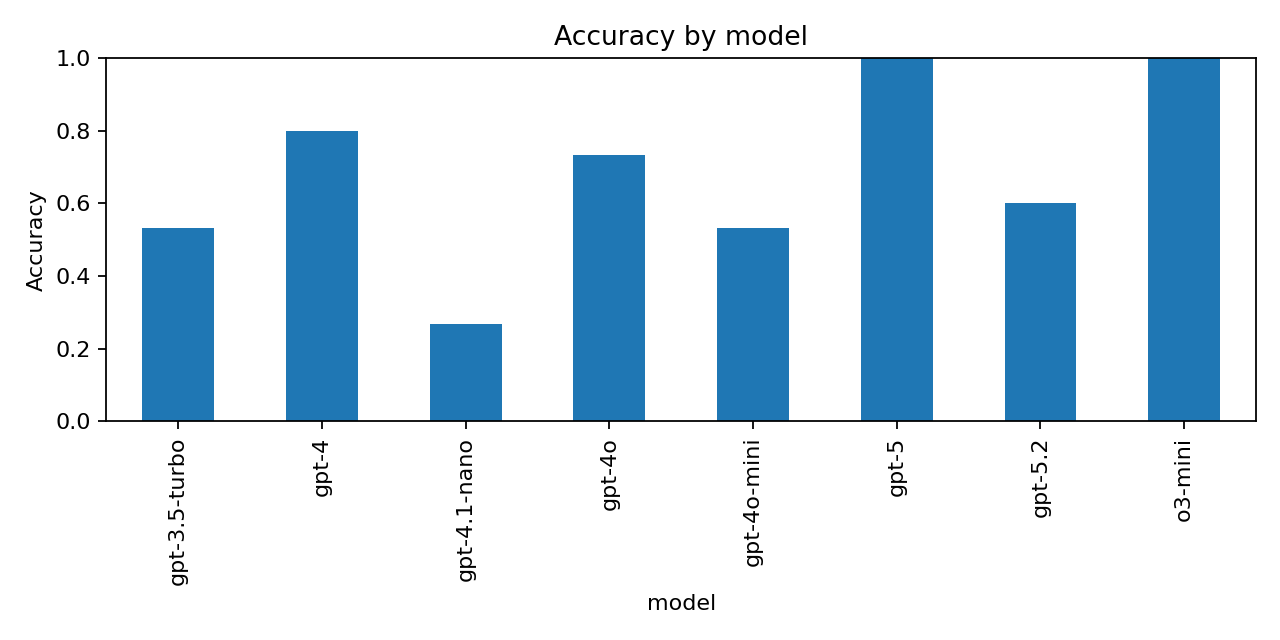
GPT-5 handled all of these questions without issue. GPT-5.2, on the other hand, was repeatedly tripped up—most notably by the strawberries example and by counting letters in a random string. Earlier models struggled too, but the step backward between GPT-5 and GPT-5.2 is hard to ignore.
So what might be going on?
One possibility is that GPT-5.2 is more heavily optimised for fluent, high-level responses, and less inclined to slow down and double-check details like character counts. Another is that changes made for efficiency, safety, or generalisation subtly interfere with this kind of mechanical reasoning. GPT-5, by contrast, may still “take the boring path” and do the counting properly.
We don’t take this as evidence that GPT-5.2 is worse overall. But it is a good reminder that progress in LLMs isn’t always a straight line. Even as models improve overall, their behaviour on specific tasks can still move backwards from one version to the next.
Conclusion
As the title suggests, asking the same questions of newer models doesn’t always produce cleaner or more predictable results. Overall performance has improved, but behaviour can still shift, sometimes forward, sometimes sideways, and occasionally backwards, from one release to the next.
These small experiments aren’t meant to rank models or draw hard lines. Instead, they’re a reminder that model progress is uneven, and that repeating the same questions over time can reveal changes that aren’t obvious from headline benchmarks alone. Same questions. New models. Mixed results.
Editor's Note
Our goal is to be careful, transparent, and repeatable in how we explore ideas, without presenting our work as formal scientific research. The experiments and analyses on this site are designed to investigate questions, test assumptions, and build intuition about how systems behave in practice.



