LLMs Are Not as Consistent as You Think

We often treat large language models as if they’re deterministic tools: ask the same question twice and you’ll get essentially the same answer. But anyone who uses them regularly knows that isn’t always true. Sometimes responses drift. Sometimes they change a lot. And sometimes they break your expectations entirely. This article digs into that everyday experience by asking a simple question: how consistent are LLMs, really, when you ask them the same thing over time?
By posing the same tricky prompt to several popular free LLMs once a day for a week, we surface patterns that are easy to miss in casual use. If you rely on LLMs for anything repeatable, predictable, or automated, the findings offer a useful reality check on just how stable their answers actually are!
Run it yourself
all of our data, code and results are available in GitHub: https://github.com/MachinesDoItBetter-ai/llm-consistency-over-time
The Experiment
Approach
The approach we used was straightforward: once a day for a week (around 9:00am AEST) we sent the same prompt to several different LLMs. The LLMs tested were:
- ChatGPT - https://chatgpt.com - Defaults to model GPT-5.1.
- Grok - https://grok.com/ - Defaults to Auto value which will typically use the Grok 4.1 Fast model.
- Gemini - https://gemini.google.com/ - Defaults to Fast value which is using the 2.5 Flash model.
All tests were conducted using an incognito browser with the default free model and no sign-in. The models listed are the defaults as of November 2025, but the service provider may change them automatically based on conditions such as system load.
The Question
We selected a challenging question to avoid the likelihood of receiving the same answer every time. The question also needed a clearly correct answer, yet one that allowed for partial correctness, for instance, a list where some items were correct while others were missing. We eventually arrived at the following prompt:
Can you list the best 5 scrabble words I can make from these letters assuming it is the first move. The word will get double score, and if long enough it will get the double letter bonus on one of the letters. Consider this position and report only the best score.
Do not provide any explanation, nor position, only the list of words and scores, with one word per line followed by its score.
Letters: BADIERK
This question involves some complex reasoning that LLMs are likely to struggle with, specifically, how the positioning of a word affects which letter receives the double score. At the same time, it allows plenty of room for partially correct answers (for example, correct words but incorrect scores). The prompt also specifies an answer format, giving us another dimension on which to test the consistency of the LLM responses.
The correct answer to our prompt is:
DEBARK 36
KEBAR 32
BRAKED 32
BARKED 32
BREAK 32
LLM Accuracy
Although the goal of the experiment was not to test accuracy, it’s important that we still consider it — otherwise we could end up rewarding a response that is consistent but nonsensical (for example, “No, I can’t do that”). To account for this, we considered several accuracy metrics:
-
Word Accuracy – Did the answer include the correct words? We compared responses against the five best words, awarding one point for each correct inclusion. We added half points for each time the two next best words,'BIKED' and 'BAKED', were included.
-
Scoring Accuracy – We were originally going to assess word scoring accuracy, but scoring accuracy was so poor that we did not report on it. You can see the scores the LLMs assigned in the raw data.
-
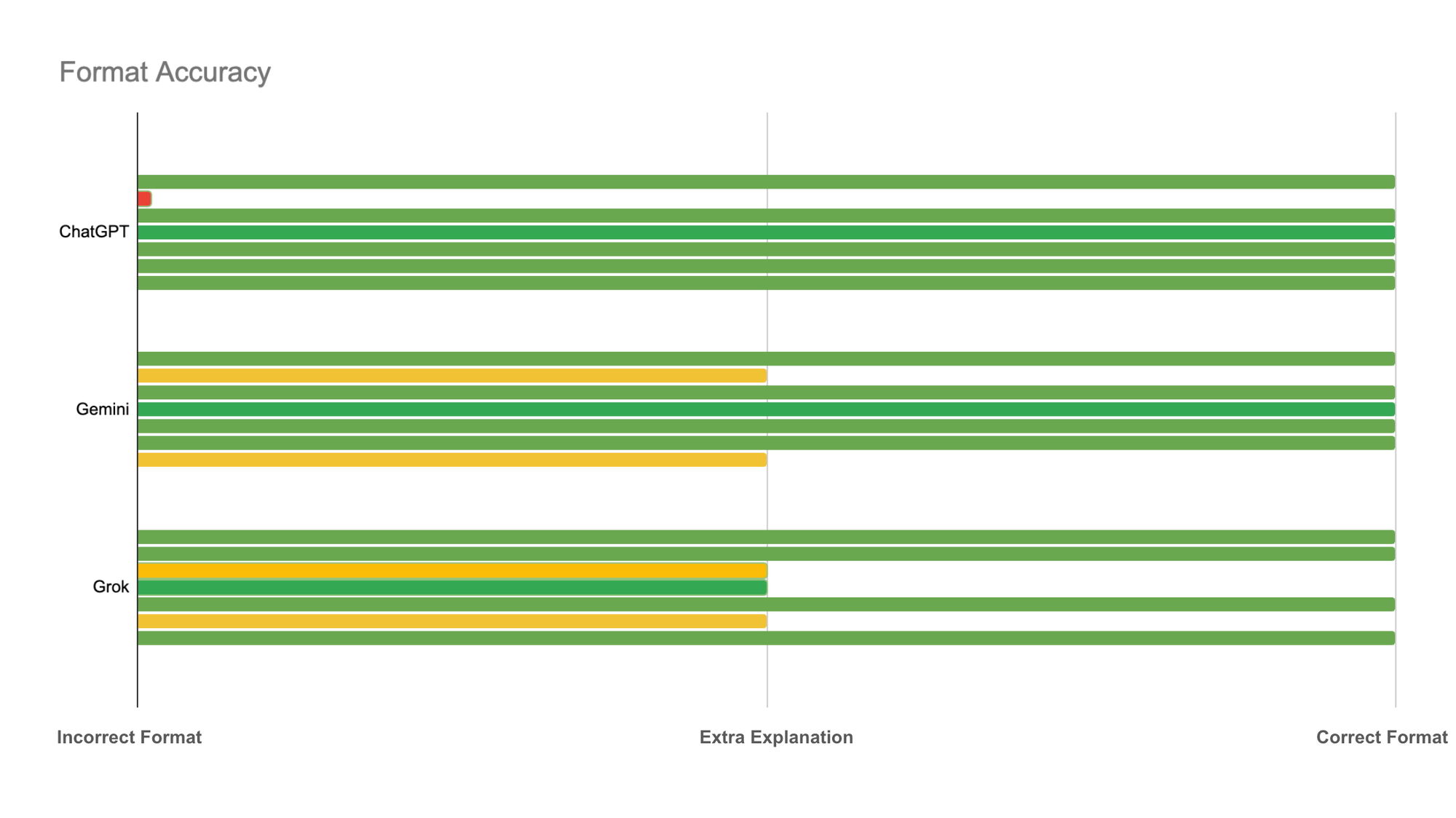
Format Accuracy – Did the response meet the formatting instructions? One point was awarded for the correct response format, we ignored case and whitespace and allowed for a points suffix or prefix like 'pts' or 'Points'. Half a point was given if the format was correct but included additional reasoning before, after, or around (but not inside) the score list. Zero points were awarded if the format was incorrect.
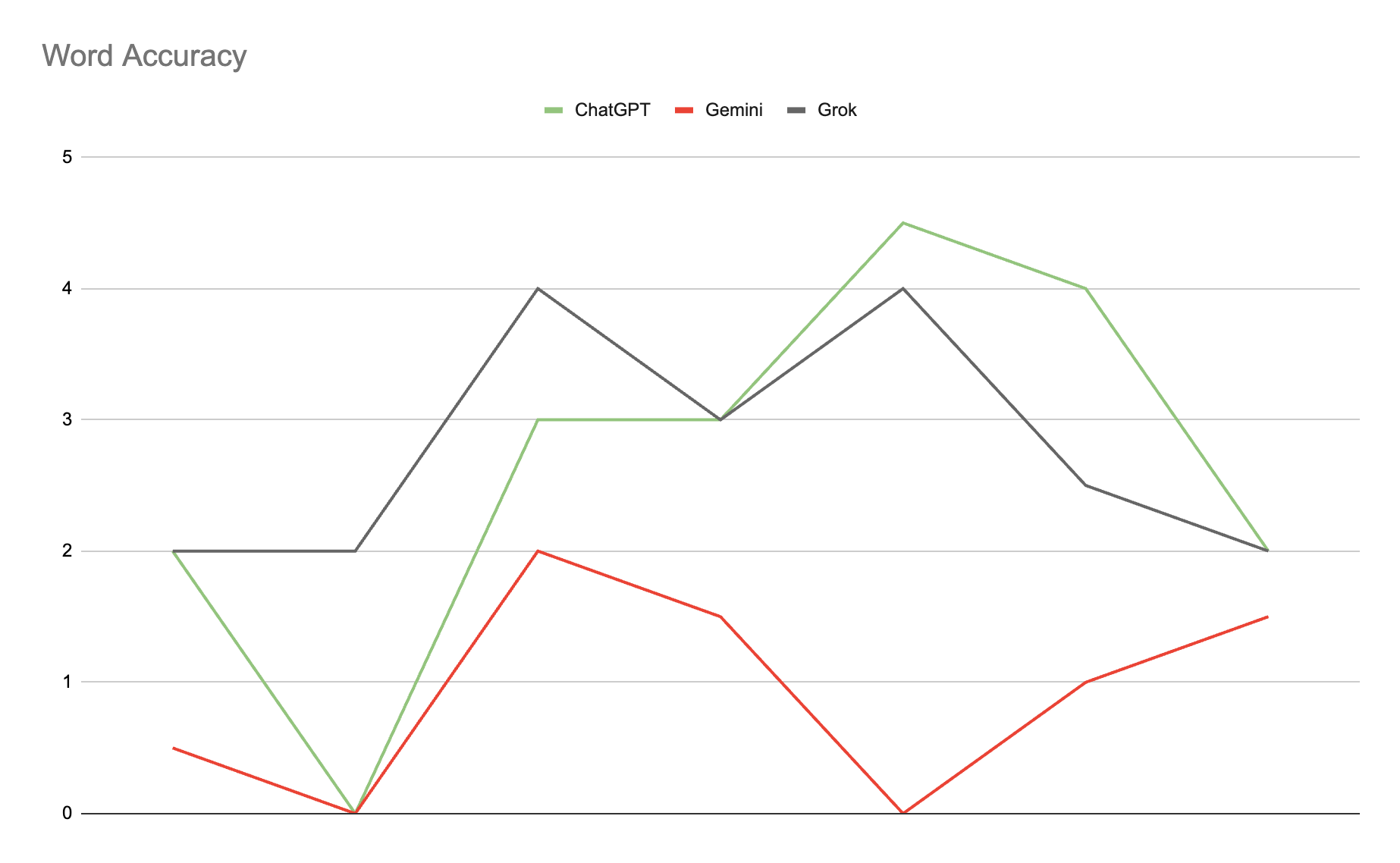
Word Accuracy
According to the Word Accuracy metric, both Grok and ChatGPT performed well, with Grok's 2.9 average score slightly edging out ChatGPTs 2.8 average score. Gemini performed significantly worse with an average of 0.9.
Format Accuracy
The formatting was generally as asked for although from time to time, at least once for each LLM, additional explanation was included (or in the case of ChatGPT it asked us to run Python rather than telling us the answer).
Consistency
We defined a measure for consistency based on vectorising the results and using cosine similarity between each pair. Specifically:
1. Converting Text to Vectors (TF-IDF)
Each LLM output is treated as a small text document.
We convert these texts into numeric vectors using TF-IDF (Term
Frequency-Inverse Document Frequency):
- Term Frequency (TF): how often a word appears in a document.
- Inverse Document Frequency (IDF): how rare that word is across
all documents.
The result is a weighted vector for each output that emphasizes meaningful or distinguishing words.
2. Computing Pairwise Similarity
Once the outputs are embedded as vectors, we compute cosine similarity between each pair:
A · B
cosine_similarity(A,B) = ---------
|A| |B|
- A score of 1.0 means the outputs are identical.
- A score of 0.0 means they share no detectable similarity.
This gives us an N × N similarity matrix, where N is the number of output files.
3. Overall Similarity Score
To make comparisons easy between runs or datasets, we produce a single scalar value:
Similarity Score = mean pairwise cosine similarity between all different files.
We ignore the diagonal (self-similarity = 1.0) so the score reflects only real comparisons.
Formally:
Σ_{i ≠ j} sim(i, j)
score = -------------------
N(N − 1)
Note:
Given the poor performance on scrabble score accuracy we considered only words in our analysis.
You can regenerate the results and include the score using the tools in the git repo.
Results
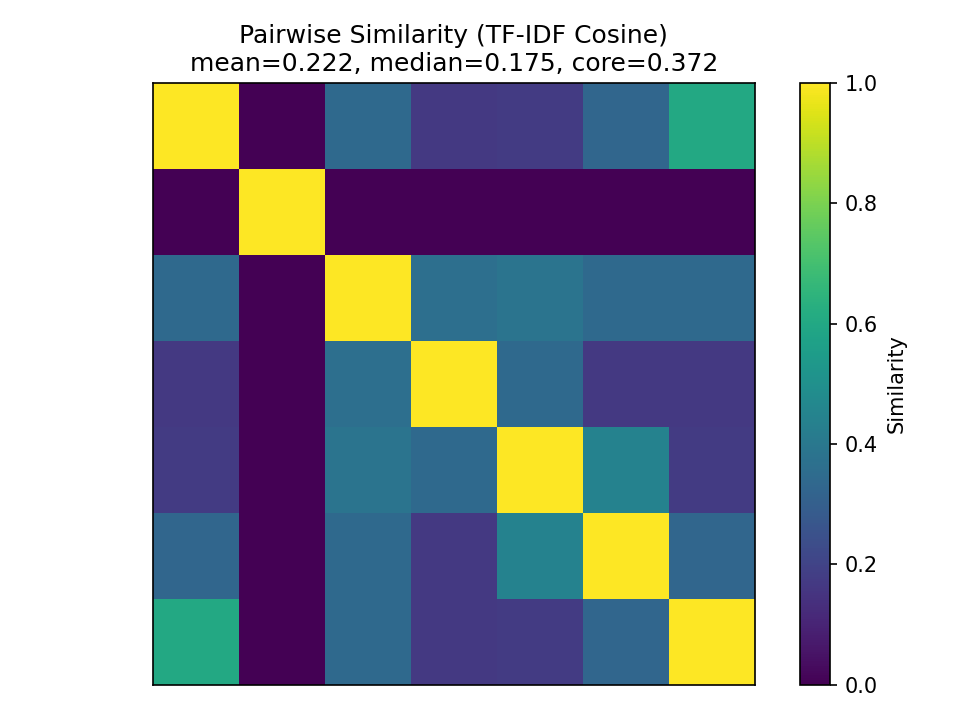
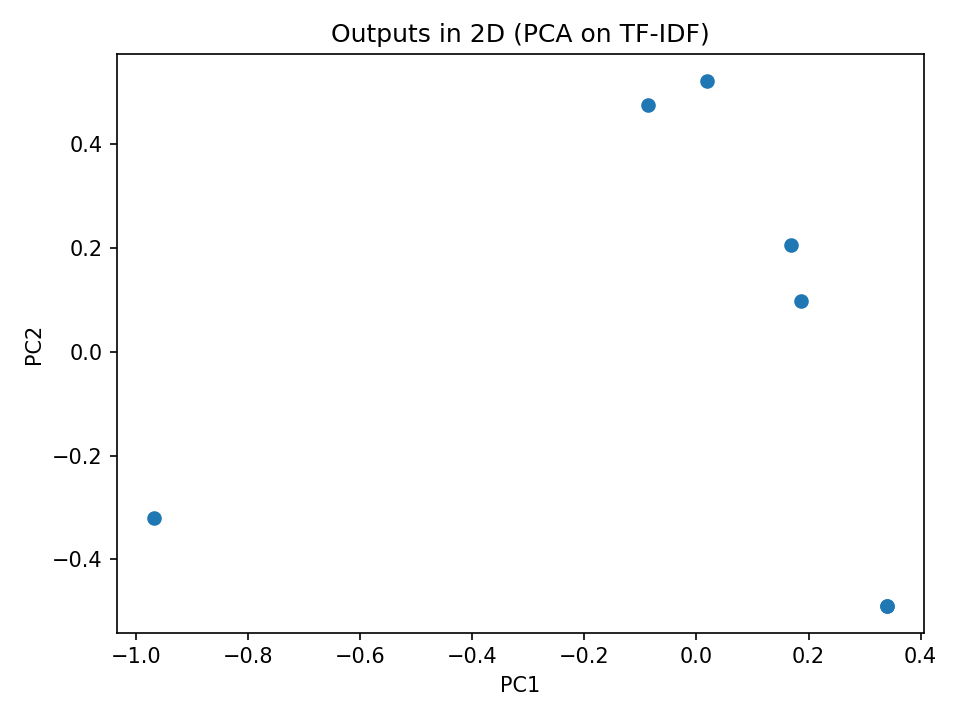
For each LLM we present a heatmap showing similarity between results and a scatter plot to reveal clustering and outliers. The scatter plot was created by using PCA (Principal Component Analysis) to reduce the vectors to two dimensions.
ChatGPT Results
ChatGPT performed the best of the three LLMs tested, with the highest mean and median. One significant outlier (which contained python code for calculating results) took down the overall scores. Interestingly, although there was a high frequency of repeat words, no two days had the same word list:
Gemini Results
Gemini performed the worst of the three LLMs, with differing formats, two instances of complex explanations, and little consistency in word lists:
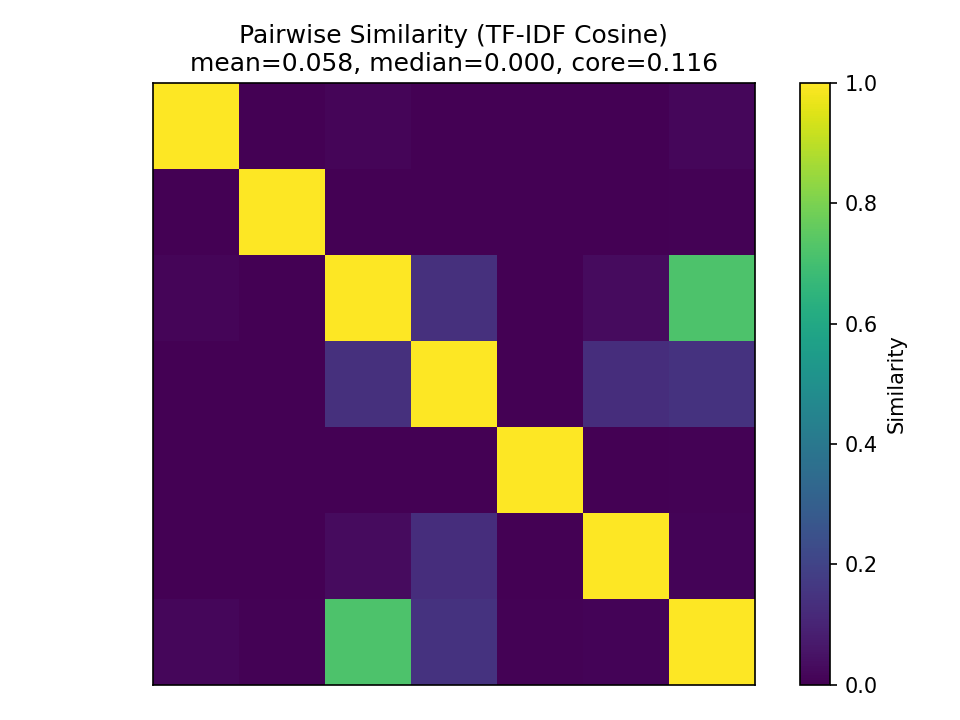
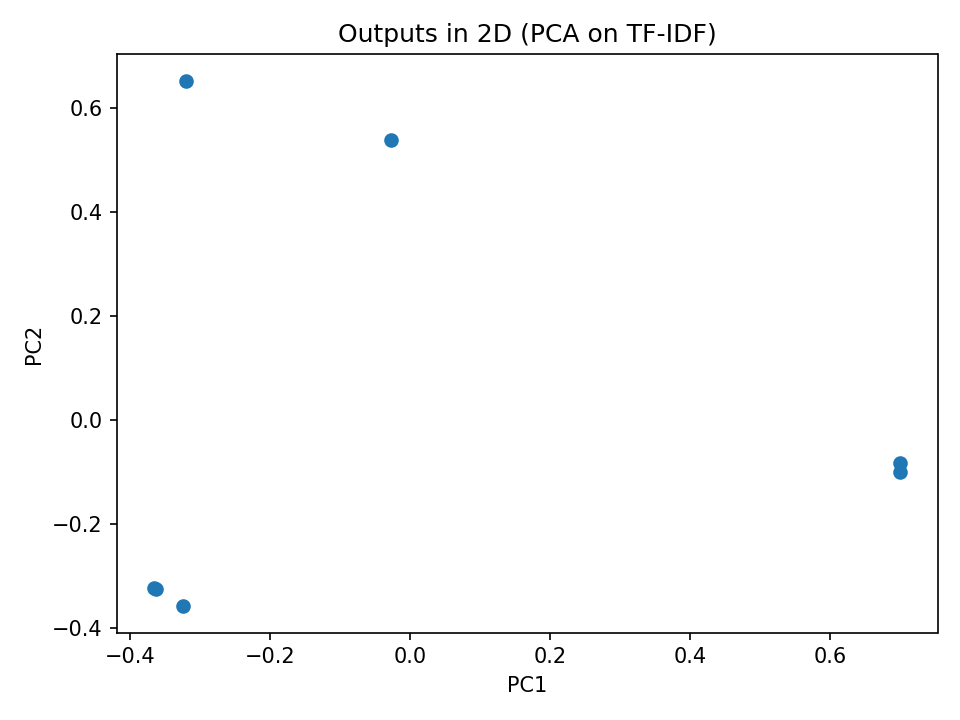
Grok Results
Grok performed in the middle of the pack, its consistency scoring was primarily hindered by its tendency to put in a line or two of explanation after a properly formatted list (which happened three out of seven times):
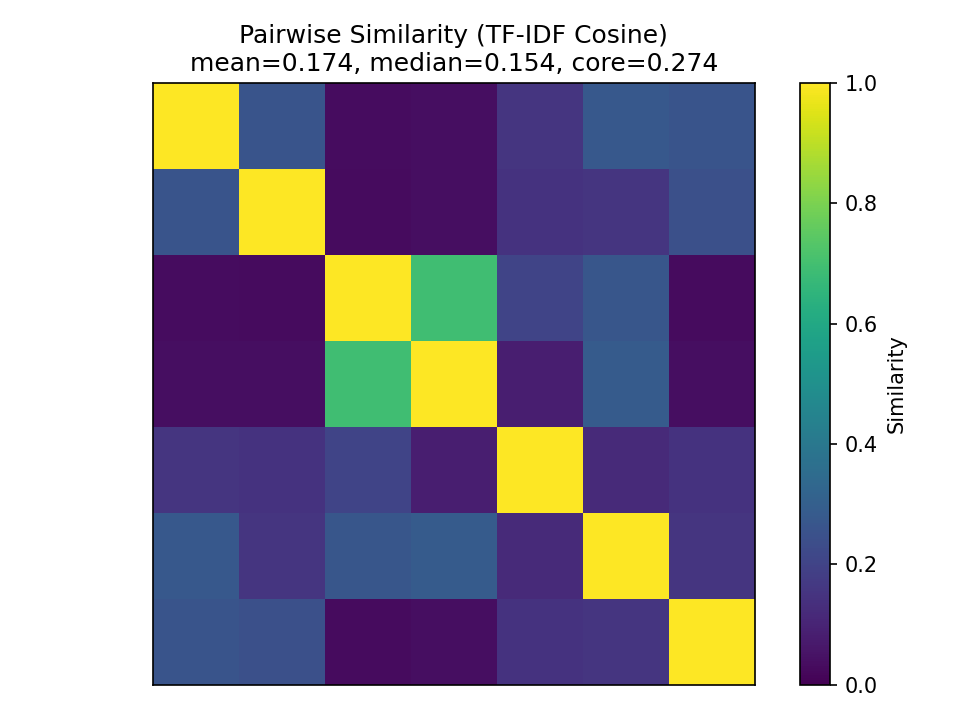
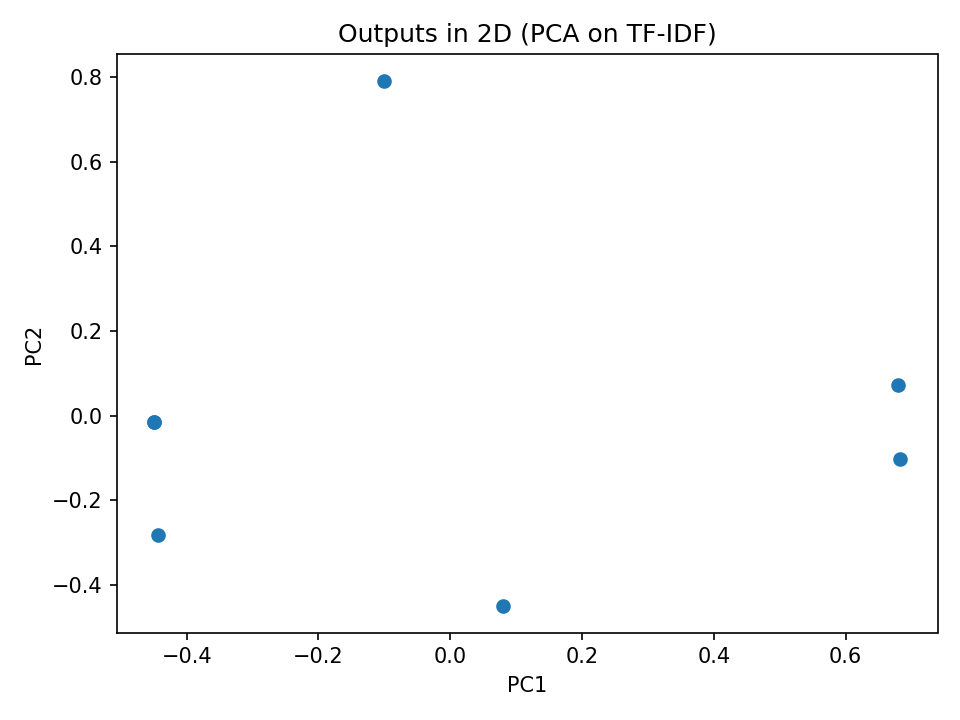
Synthetic Data Set
To demonstrate the effectiveness of the method at revealing consistency we also created a synthetic data set where all results were correctly formatted and had only slight deviations from each other, here are some samples from the data set (the full data set is available in the git repo):
synthetic-1 synthetic-3 synthetic-5
------------ ------------ ------------
DEBARK 36 RIDER 32 RIDER 30
KEBAR 32 KEBAR 36 KEBAR 28
BRAKED 32 BRAKED 36 WRONG 28
BARKED 32 BARKED 36 BAKER 28
BREAK 32 BREAK 36 BREAK 28
This produced the following heatmap and scatter plot:
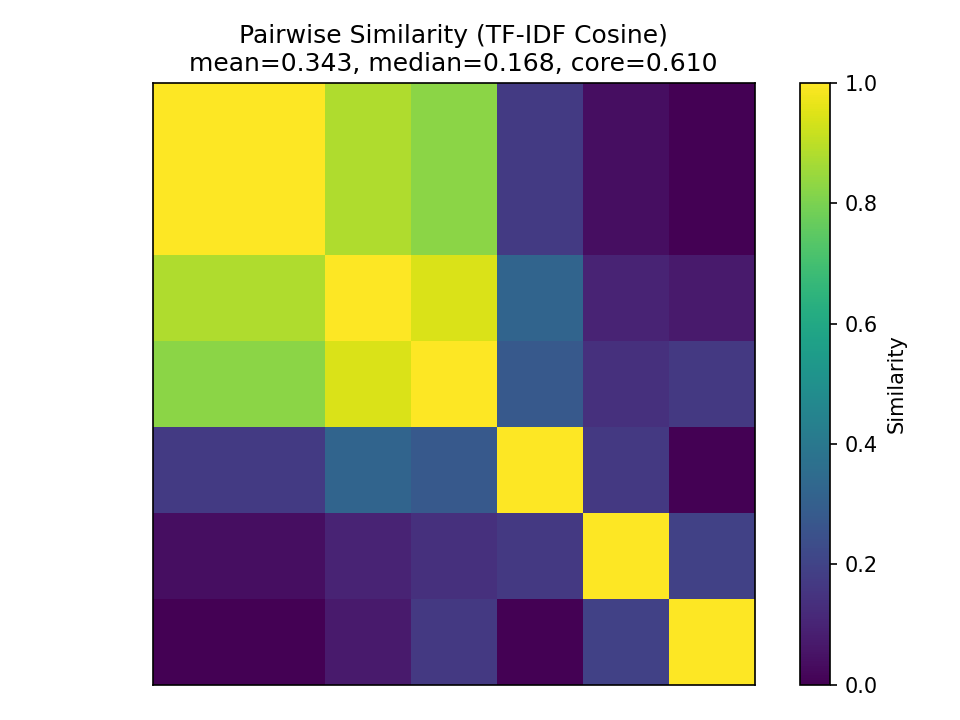
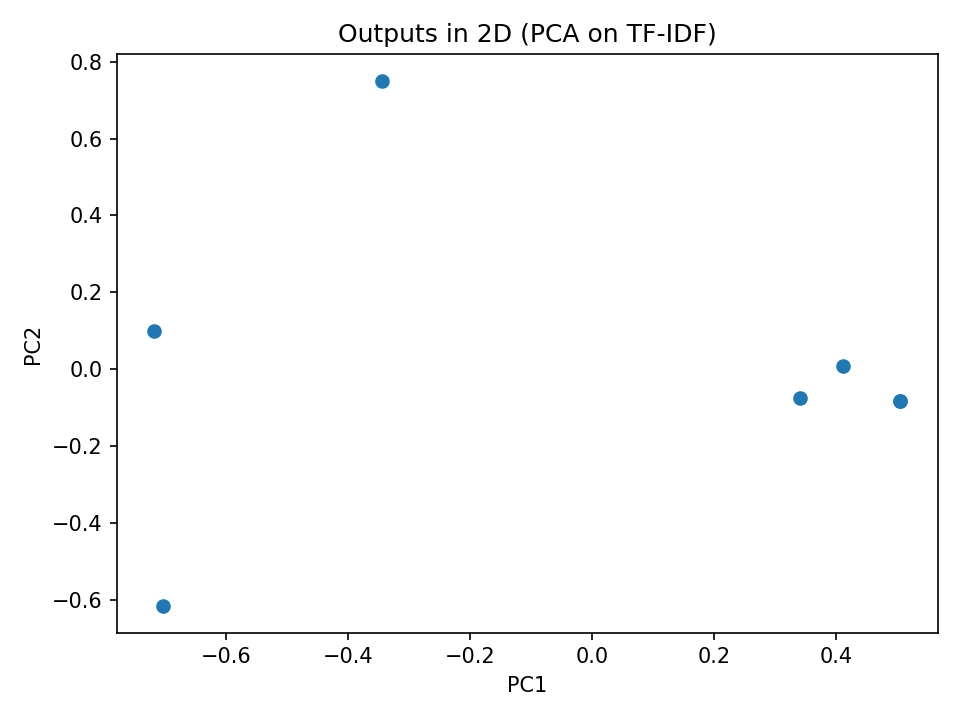
Conclusion
This small, repeated experiment highlights a key but often overlooked property of LLMs: their outputs are not stable over time, even when the prompt and conditions remain unchanged. Day-to-day variation showed up not only in wording, but also in structure and formatting, producing measurable differences between runs. These shifts appear without any explicit signal to the user that the underlying model, routing, or generation conditions may have changed.
The broader takeaway is that consistency should be treated as a first-class concern when using LLMs, especially in contexts that assume repeatability. Even modest variability can introduce noise, regressions, or unexpected behavior in downstream systems. Understanding and accounting for this inherent instability is essential when LLMs move from experimentation into routine or automated use.
Editor's Note
Our goal is to be careful, transparent, and repeatable in how we explore ideas, without presenting our work as formal scientific research. The experiments and analysis on this site are designed to investigate questions, test assumptions, and build intuition about how systems behave in practice.



